Generative AI Art
Generative artificial intelligence art has undoubtedly become one of the most fascinating topics of the past five years, emerging as the most significant technology of 2023. While it has divided AI developers and conservative artists into two opposing camps worldwide, it has forced companies and governments to reach consensus on new regulations. End users struggle to distinguish between what’s created with AI and what are actual images. While part of society feels unsettled by this rapidly advancing technology, others quickly adapt and integrate it into their lives. On our social media accounts, we’ve created selfies reminiscent of works by famous 16th-century artists like Jacques-Louis David, swapped our faces with those of celebrities, or transformed ourselves into cartoon characters. In essence, we’ve become entities that exist simultaneously in both real and virtual worlds, today and in future periods.

Left: Real painting, Right: AI model output trained on real artworks
It’s no exaggeration to say that 2023 was a period when AI’s cumulative effects from the past decade reached their peak and penetrated every aspect of our lives. Today, almost every company desires to add AI integrations to their products. People are installing applications on their smartphones that allow them to ask questions quickly and receive instant answers. Meanwhile, major tech companies are also directing their goals toward AI-focused technologies. There’s certainly a reason why these developments have progressed on both natural language and visual perception fronts. This technological revolution became possible with the emergence of two innovative technologies: the "Attention Is All You Need" paper published by Google in 2017 and what we call the "Diffusion Architecture." These studies are the foundational pillars that accelerated AI’s development and made it an indispensable part of our daily lives.
Generative art has held an important place in our lives since the 1960s. During this period, the first fundamental and simple examples of this art occupied an experimental and avant-garde position. Between 1960 and 1965, artists producing these works used the term "generative art" in the context of computer-generated geometric shapes and algorithmically produced outputs. One of the pioneers in this field, whom I had the opportunity to work with, was Vera Molnar, a Hungarian media artist born in 1924 who unfortunately passed away in December 2023, just a week before her 100th birthday. Besides being a pioneer of generative art, Vera Molnar was one of the first women to use computers in producing these artistic works. Her work represents innovative approaches at the intersection of art and technology, laying the foundations for today’s understanding of digital art.

Generative art has caused chaos and sensational debates in the art world throughout every period of its existence. One of the most fundamental questions that comes to mind about this art form concerns ownership when a work is created: Who is the creator of the piece—the programmer who developed the algorithm, the algorithm or AI model itself, or the artist who envisioned the work and reflected their own story and style? This topic has always been controversial. The developed software or AI model can be likened to systemic autonomy. On one side, there are human artists who create works using brush and canvas, relying on their neural motor systems, while on the other side, there are programmers who establish algorithms, shape them, and create art through this means. This is a dilemma that invites deep reflection on the definition and boundaries of art.
When we move past these sensitive issues, we find ourselves at a point today where we have AI technology that can successfully pass Turing tests, sometimes frightening us, sometimes exciting us. I’ll touch on the fascinating mathematics behind these works that plays a major role in our creation of them. Of course, these developments depend on how far hardware and software technologies have advanced. However, creating these artworks requires quite high computational power. If you have hundreds of graphics cards, powerful processors, good mathematics and statistics knowledge, and also possess an artistic and aesthetic soul, you can become a generative AI art developer. This is an extremely original and innovative field where both technological and artistic talents converge.
Generative AI Art
The term "generative AI" is used to describe AI models developed for producing media in text, visual, audio, or different formats. This field also includes text-based question-answer AI technologies like ChatGPT, which are widely used today. While areas like music, poetry, or literature are important parts of art, due to the technology’s development process, generative AI art is often mistakenly associated specifically with the visual domain. In this article, I’ll primarily address generative AI art in the visual context.

Modern Asian Ukiyoe Edo Style Art, Mert Cobanov, 2023.
In the early periods of generative art, models were generally developed using simpler mathematical programming techniques. Additionally, robotic arms, random number generators, and various algorithms were used more frequently. Over time, the development of image processing techniques and the idea of combining these techniques with deep learning enabled AI to take a more active role in art production. These developments paved the way for generative AI art to evolve into its current sophisticated and visually rich form.
AICAN
One of the pioneering examples in this field is the AICAN (Artificial Intelligence Creative Adversarial Network) system developed by Dr. Ahmed Elgammal and his team at Rutgers University. AICAN is a generative AI model trained on various art styles including Baroque, Rococo, and Abstract Expressionism. One of the most striking features of this system is its ability to discover and create entirely new art styles never seen before. Fundamentally, it works on generating new visuals by manipulating the variables of an artificial neural network trained to produce visuals. In the image below, you can see a generative AI artwork created by the AICAN system.

AICAN redefines AI’s role in the art world and creates a significant impact on the future of art by transforming traditional art understandings. This system presents a concrete example of how technology and art together can produce new aesthetic understandings and creative expressions.
CLIP
CLIP, developed by OpenAI, emerges as an important innovation in the field of AI architecture. Many current artistic models are based on this architecture. CLIP’s specialty lies in its intelligence model that matches images with their descriptions. In other words, it matches text and visual content in a semantic context, in a common space. Our ability to define all images and their corresponding descriptions in a matrix within a mathematical space has become possible thanks to this model. Its most impressive feature is that it enables text-to-image generation and image-to-text creation. This is a technology that allows us to establish rich and complex interactions between text and visual content, thus taking AI’s creative potential to new dimensions.

GANs
GANs, or Generative Adversarial Networks, are fundamentally a type of machine learning algorithm consisting of two neural networks: a generator and a discriminator. The generator network produces new data samples similar to the training dataset, such as images or sounds, while the discriminator network learns to distinguish between generated samples and real ones. Through a competitive process, the two networks compete with each other until the generator produces realistic samples that can fool the discriminator.
In the context of Generative Adversarial Networks (GANs), the "latent space" refers to the input variables used to generate images or other data. In a GAN, the generator network takes a series of hidden variables as input and produces an image or other data based on these variables. The discriminator network evaluates the generated output and provides feedback on how the generator can improve its output.

The goal of training a GAN is to learn the mapping between the latent space and the data domain, so that the generator network can produce realistic and high-quality outputs based on a specific set of hidden variables.
Subsequently, a new technique was developed that could be used to control the mentioned latent space. This technique was the idea of using the CLIP model I mentioned earlier to control our GAN model. We already had an AI model that matched images with outputs, and now being able to control our AI model trained on images with prompts became an extremely impressive development. This is one of the fundamental building blocks of all the techniques we use today, like stable diffusion.
Diffusion
And now we can say we’ve reached the revolutionary architecture that initiated the golden age of generative AI art. You’ve probably encountered visuals on Twitter or other social media platforms recently that bring your ideas or dreams to life with simple sentences (prompts) using tools like Midjourney or Stable Diffusion.
Actually, such works are products of an AI architecture called "Latent Diffusion." Latent diffusion models work by learning the statistical distribution of training images and using this distribution to create new, unique images. These AI models, by learning billions of photos and their accompanying descriptions, allow you to create new visuals. After the model is trained, it’s possible to create new, unique visuals through sampling from the learned distribution.
This sampling process involves selecting a random point in the model’s latent space, corresponding to a unique set of features that define an image. The model generates visuals based on different points in the latent space, thus creating different images that resemble the original training images in terms of style and content. You can control this complex process simply by putting your imagination into writing (as we used in the CLIP model), which opens new horizons at the intersection of artistic expression and technology.
Technical Details
The Stable Diffusion model integrates a series of complex components in the image generation process. These include VAE (Variational Autoencoder), Tokenizer and Text Encoder, UNet, and Scheduler.
The fundamental purpose of the diffusion process is to gradually add noise to photographs and ensure the model learns how to remove this noise at each step. In the model’s inference phase, we expect it to generate visuals by removing the random noise input we provide. The noise addition process occurs in a non-linear manner.

The Noise Schedule determines how much noise will be added at different time steps. For example, an approach defined in the ’DDPM’ ("Denoising Diffusion Probabilistic Models") paper describes the noise addition process.

The noise addition process in diffusion models doesn’t occur linearly. A linear noise addition process would cause the photo to quickly transform into a completely noisy form. Therefore, a cosine approach is used for a more controlled noise addition process.
The scheduler has two fundamental tasks:
- Adding noise to the image iteratively along with the scheduler.
- Determining how the image will be updated in the next time step while removing noise from the photo.
In diffusion models, VAE is used. This provides a smaller representation of the image in a latent space. For example, a 512x512x3 sized image is reduced to 64x64x4 dimensions.
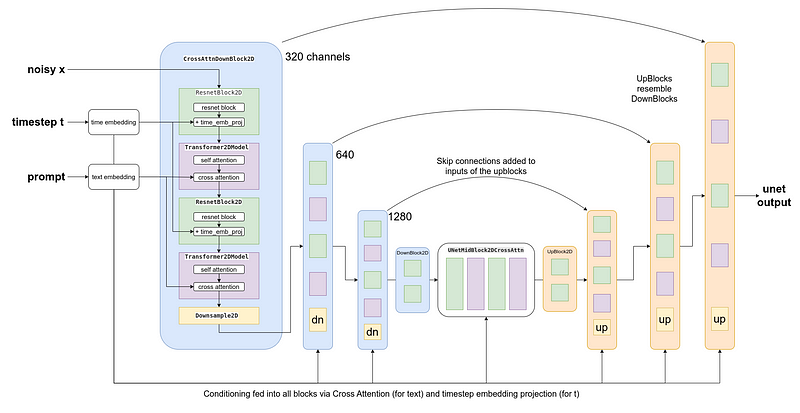
Text Conditioning is the addition of text data as information to influence the image creation while training the diffusion model. The goal here is for the model to decode noise appropriately according to the text when given a noisy image, and for the image to be created accordingly.
During inference, pure noise and text compatible with the image we want to create are initially given, and the model is asked to generate from random input according to the text. The CLIP model is again used to create text conditioning.
Cross Attention: Since the model’s final output is quite dependent on the initially used noise input, a method called Classifier Free Guidance (CFG) is used to balance this situation. Briefly, the model is trained without text information during training, and during inference, two predictions are made with zero conditioning and text conditioning. The difference between these two predictions is called CFG.
There are also different conditionings like Super-resolution, Inpainting, and Depth to Image. While super-resolution involves training on high-resolution and low-resolution versions of photos, depth to image is trained by conditioning on the image itself and its depth map.
Conclusion
As I close this article, I must note that generative art is neither completely art in the traditional sense nor merely a programming discipline. Actually, it can be defined as both and neither. Software, by definition, is a communication interface between humans and computers. Art, on the other hand, is a field deeply connected with emotions, and it would be wrong to limit such an emotional subject with a single definition. Generative art brings together these two vast and different worlds. Generative AI additionally adds deep mathematics, mimics humans, and shakes our perception of reality. It’s still too early to make a definitive judgment on this matter. Generative art is a field that exists at the intersection of art and technology, constantly evolving and pushing boundaries.